BHC - Dokumentace
Uživatelská dokumentace
Program BHC slouží ke komprimaci a dekomprimaci souborů.
Ovládání
Ovládání probíhá přes příkazovou řádku. První parametr určuje, jaká akce se vykoná:
| a | Zapakovat do archivu |
| l | Vypsat obsah archivu |
| x | Rozpakovat z archivu |
Druhý parametr určuje jméno archivu. Je nepovinný a jestliže není uveden, použije se jako jméno archivu jméno aktuálního adresáře. Jestliže je aktuální adresář kořenový, použije se jako jméno archivu jmenovka disku. Jestliže je jméno archivu uvedeno bez koncovky, přidělí se mu koncovka .bhc (nebo .exe v případě samorozbalitelného archivu). Jestliže druhý parametr není jednoznačné jméno souboru (začíná !, končí \ nebo obsahuje ? nebo *), pracuje se s ním jako s třetím parametrem a jméno archivu se zvolí dle předchozího postupu.
Další parametry určují, s jakými soubory se bude pracovat. Jsou povoleny expanzní znaky obvyklé v DOS: ? a *. Otazník znamená, že se na jeho místě může vyskytovat právě jeden libovolný znak. Hvězdička znamená, že na jejím místě může být libovolný počet libovolných znaků. Je-li první znak parametru !, znamená to, že se se soubory dané masky naopak pracovat nemá. Začíná-li už první souborový parametr vykřičníkem, předřadí se mu maska *.*, aby bylo z čeho vylučovat. Pozdější parametry přehlušují nastavení dřívějších. Chceme-li například zapakovat všechny soubory kromě souborů *.tmp, ale přece jen soubor test.tmp, použijeme příkaz: bhc.exe a !*.tmp test.tmp.
Místo jména souboru se může uvést také jméno adresáře. Jestliže se komprimuje, bude se komprimovat obsah daného adresáře, jestliže se dekomprimuje, bude se do daného adresáře dekomprimovat. Že jde o jméno adresáře lze vynutit tím, že bezprostředně za jeho jménem následuje znak \.
Kdekoliv na příkazové řádce může být umístěno číslo v rozmezí 1000 až 50000 určující, s jak velkým bufferem se má pracovat. Udávaná velikost je v bytech. Větší velikost bufferu má lepší výsledky na datech, která mají v celém souboru podobnou četnost znaků (například texty), menší velikost je lepší na data, která mohou mít v různých částech souboru různou četnost znaků (například spustitelné soubory nebo obrázky). Standardní velikost bufferu je 30000 a dává dobré výsledky pro většinu dat.
Přepínače
Kdekoliv na příkazové řádce mohou být rozmístěny přepínače ovlivňující chování programu. Přepínač je kterýkoliv parametr, který začíná znakem / nebo -. Za tímto znakem může být jeden nebo více znaků, které jsou nadále považovány za přepínače. Seznam přepínačů a jejich funkcí:
| a | Obnovit původní atributy, datum a čas souboru |
| d | Ukládat absolutní adresářové struktury včetně názvu disku |
| e | Smazat zpracované soubory |
| i | Vstup brát ze standardního vstupu |
| l | Jména souborů brát ze souborů na příkazové řádce |
| m | Archiv rozpakovat do nového adresáře |
| n | Ukládat pouze jména souborů bez adresářových struktur |
| o | Výstup dávat na standardní výstup |
| p | Ukládat absolutní adresářové struktury kromě názvu disku |
| r | Procházet strukturu podadresářů |
| s | Nevypisovat žádná hlášení, neklást žádné dotazy |
| x | Vytvořit samorozbalitelný archiv |
| z | Zprávy vypisovat na standardní výstup místo na chybový |
Program umožňuje vytvoření samorozbalitelného archivu. Archiv potom obsahuje program i data. Rozbalení se uskuteční prostým spuštěním tohoto archivu. Jinak lze takovýto archiv používat stejně jako program. Lze z něj vytvořit i původní verzi programu bez dat: archiv.exe a /x bhc.exe .x. Zápis znamená: Použij programový kód samorozbalitelného archivu archiv.exe na vytvoření nového samorozbali-tel-ného archivu bhc.exe, do kterého nepřidávej žádné soubory (soubor jménem .x neexistuje).
Návratové kódy
Program vrací hodnotu, která lze použít například v dávkových souborech příkazem errorlevel. Jestliže vše proběhne v pořádku, vrátí program 0, jinak vrátí nenulovou hodnotu podle toho, jaký druh chyby nastal:
| 1 | vstupně / výstupní chyba |
| 2 | nedostatek paměti |
| 3 | chyba na příkazové řádce |
| 4 | poškozená data |
| 5 | přerušení od uživatele |
Technická dokumentace
Tato část dokumentace popisuje především strukturu archivu. Měla by být dostačující pro napsání algoritmů pracujících s daty BHC (například interní dekomprimace v manažeru souborů).
Huffmanův algoritmus
Huffmanův algoritmus pracuje tak, že projde blok dat, zjistí množství jednotlivých znaků a podle jejich četnosti jim přiřadí bitové kódy. To dělá tak, že spojí dva prvky s nejmenší četností do jednoho a přiřadí mu četnost odpovídající součtu četností spojených prvků. Tuto činnost opakuje tak dlouho, dokud existuje více než jeden prvek. Tímto způsobem postaví jakýsi strom, který potom ohodnotí tak, že levým synům přiřadí kód 0 a pravým synům kód 1. Každý prvek potom bude mít jednoznačný bitový kód, který nebude prefixem žádného jiného. Délka kódu každého prvku bude odpovídat jeho hloubce ve stromu. Příklad bude jistě názornější:
| Četnost jednotlivých znaků:
|
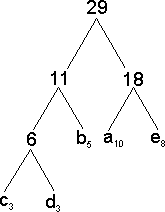 |
Bitové ohodnocení znaků:
|
Dále algoritmus pracuje tak, že načítá znaky ze vstupního souboru a do výstupního souboru ukládá pouze bitové ohodnocení těchto znaků.
Formát archivu
| { | opakovat pro všechny soubory |
| jméno souboru | může obsahovat absolutní nebo relativní adresářovou cestu, oddělovač je znak \ |
| 00 | byte s hodnotou 0 |
| atributy, datum, čas | 5 bytů, vlastnosti souboru, u data a času se jako první ukládá významnější byte |
| délka souboru | 4 byty, délka zapakovaných dat v bytech |
| { | opakovat, dokud není přečtený celý soubor |
| strom | viz dále |
| data | viz dále |
| terminátor | příznak ukončení vstupních dat (bufferu nebo souboru) |
| indikátor | jeden bit určující, zda další data patří ke stejnému (0) nebo k dalšímu (1) souboru |
| 0 | vyprázdnění bitového bufferu |
| } |
Jestliže má komprimovaný soubor nulovou délku, uloží se pouze délka souboru.
Struktura stromu
Stromem se prochází do hloubky. Pro každý uzel se uloží bit 0, pro každý list se uloží bit 1 následovaný osmi bity s kódem listu. Jestliže kód listu má hodnotu 0 nebo 256 (terminátor), uloží se ještě jeden rozlišovací bit. Kód terminátoru je tedy 1000000001. Uloženým stromem se při načítání postupuje takto: Jestliže narazíš na bit 0, vytvoř z aktuálního prvku uzel a postup do levého následovníka. Jestliže narazíš na bit 1, načti dalších osm (devět) bitů, ulož je do listu a postup na nejbližší volný prvek napravo. Načítání stromu skončí v momentě, kdy už není žádný volný prvek. Tímto způsobem se vygeneruje strom, kterým se při zpracování dat prochází.
Struktura dat
Data je posloupnost bitů, kterou se prochází tímto postupem:
- Začni v kořeni stromu
- Jestliže načteš bit 0, postup do levého následovníka, jestliže bit 1, postup do pravého následovníka
- Bod (2) opakuj, dokud je číslo aktuálního uzlu větší než 256
- Jestliže je číslo uzlu menší než 256, zapiš daný znak, jinak přečti další bit, který ti řekne, co dělat dál
Vývojářská dokumentace
Tato část dokumentace shrnuje, jak jsem při vývoji programu postupoval, proč zrovna tak a na jaké problémy jsem při tom narazil. Mohla by být k užitku někomu, kdo by chtěl podobný druh programu napsat.
Moduly
Kromě hlavního modulu vznikl ještě modul na bitový přístup k souborům bitio. Jsou v něm funkce na čtení a zápis do souboru po bitech. Pro tento účel také vznikl datový typ BITFILE, který kromě ukazatele na soubor obsahuje ještě buffer na nekompletní byty.
Struktura archivu
Protože se v archivu mnohokrát ukládá strom výskytů, bylo potřeba ho navrhnout co nejúsporněji. Jako první jsem vyloučil možnost ukládat četnost jednotlivých znaků. Díky omezené maximální velikosti bufferu a tím i počtu jednotlivých znaků by se sice vešel jeden znak do tří bytů (jeden byte kód znaku, dva další jeho počet), pořád by to bylo ale značné plýtvání. Zvolil jsem proto možnost ukládat přímo podobu stromu. V technické části dokumentace je popsáno, jak přesně.
Délka souboru ukládaná v archivu je čtyřbytová položka určující délku zapakovaného souboru v archivu. Ukládá se hlavně proto, aby bylo možné snadno přeskakovat soubory, které se nemají rozbalovat (například všechny při vypisování obsahu archivu). Dále slouží k tomu, aby bylo možné v průběhu rozbalování vypisovat procentuální ukazatel činnosti. Čtyři byty jsou většinou zčásti nevyužité (lze je použít i pro maximální velikost souboru dovolenou DOSem - 232 = 4 GB, průměrná délka souboru je ale o mnoho řádů nižší). Proto jsem také zvažoval možnost ukládat tuto délku pakovaně (například pět bitů určujících počet platných číslic, následovaných dalšími bity se skutečnou hodnotou). Nakonec jsem však od této myšlenky upustil, protože délka se ukládá až po uložení dat a na začátku je nutné vyhradit na tuto délku přesné místo.
Po zapakování každého souboru se vyprázdní bitový buffer. Mohlo by se to zdát jako plýtvání, ale má to své opodstatnění. Jeden důvod je ten, aby název souboru byl čitelný i při prostém zobrazení obsahu archivu (chci vědět, jestli je v archivu soubor daného jména a nemám k dispozici žádnou utilitu). Další důvod je, že by v délce souboru nestačilo uložit délku v bytech, ale bylo by nutné ukládat délku v bitech. Tím by se prostor na uložení délky zvětšil o tři bity a značně by se zkomplikovala jakákoliv operace s ní.
Samorozbalitelný archiv je dělaný tak, že jsou za programový kód přidána data archivu. Při spuštění programu se nejprve skočí za programový kód (jehož délka se načte z hlavičky spustitelného souboru) a zjistí se, zda tam jsou data (a jde o samorozbalitelný archiv) nebo konec souboru. Program musí být bez ladících informací, které za něj přidává kompilátor. K oříznutí těchto informací lze použít program tdstrip nebo postup na vytvoření původního programu bhc.exe, který je uvedený v uživatelské části dokumentace.
Funkce
Nejdůležitější funkce jsou compress a extract, ve kterých je obsažen celý algoritmus komprese a dekomprese.
| error | vypsání kritické chyby, ukončení programu |
| print?f | funkce pro jednotnou podobu vypisovaných zpráv |
| overwrite | komunikace s uživatelem během přepisování souborů |
| strcmpe | porovnání řetězce s expanzními znaky (?*) s jiným řetězcem |
| read_tree | rekurzivní načtení stromu z archivu |
| extract | rozbalení jednoho souboru z otevřeného archivu, algoritmus dekomprese |
| read_header | načtení hlavičky souboru (jméno a atributy) |
| extract_files | rozbalení souborů v archivu, algoritmus porovnávání souboru s maskami |
| build_tree | postavení stromu podle četností jednotlivých znaků Huffmanovou metodou |
| write_tree | rekurzivní vygenerování kódů znaků, zápis stromu do archivu |
| compress | zabalení otevřeného souboru do archivu, algoritmus komprese |
| write_header | zápis hlavičky souboru (jméno a atributy) |
| expand_mask | nahrazení masky seznamem souborů, případný rekurzivní průchod podadresářů |
| compress_files | vytvoření jednoznačného seznamu souborů, zapakování všech souborů |
| help | vypsání všeobecné nápovědy, ukončení programu |
| main | zpracování příkazové řádky, otevření archivu, volání patřičné funkce |
Pro vypsání obsahu archivu neexistuje žádná speciální funkce, vypsání je pojato jako speciální případ dekomprese.
Problémy
Soubory stdin a stdout jsou otevřeny jako ASCII, což se vůbec nehodí pro bitové operace. Potřeboval bych je otevřít jako binární nebo najít funkci, která konverzi znaků u souborů otevřených jako ASCII neprovádí. Pomocí příkazu _streams[1] = *freopen("CON", "wb", stdout) se mi sice podařilo standardní výstup otevřít jako binární, ale výstup potom směřoval přímo na konzolu, takže nešel přesměrovat do souboru.
Rychlost komprimace se mi podařilo zlepšit zhruba na úroveň konkurenčních programů, dekomprimace však trvá mnohem déle. Předpokládám, že to je tím, že ostatní programy používají slovníkovou metodu, která je při dekomprimaci rychlejší.
Značné problémy mám s pamětí. Nevím, jak naalokovat více než 64 KB. I když při každé alokaci kontroluji, zda proběhla správně, program při velkém množství zpracovávaných souborů skončí nepříjemnou chybou Stack overflow. Zkoušel jsem i různé paměťové modely, ale nepomohlo to.